Salary Cleansing

Data cleaning plays a pivotal role in the realm of data analysis, serving as the foundation upon which accurate and meaningful insights are built. At its core, data cleaning is about refining raw data to remove inconsistencies, errors, and redundancies.
Despite its crucial role in ensuring the integrity and reliability of data analysis, data cleaning is often overlooked or underestimated. This oversight can have significant implications for the accuracy and validity of analytical results. There are several reasons why data cleaning is often overlooked.
- Time Constraints: Due to pressure of producing results as fast as possible, data cleaning is often given less time than required.
- Complexity: Data cleaning is a complex and iterative process and required deep understanding of both the business and data formats. Most of the time, key business process holders are not involved throughout the process.
- Less Glamorous: Developers often want to focus their attention on steps which generate tangible results like machine learning and visualizations therefore giving data cleaning less importance than deserved. It is seen as routine and mundane by many as it requires quite a lot of time and manual effort.
The Dataset
We will be looking at a salary dataset gathered using a google form. The dataset is a real-world salary data from all over the world and has not been sanatised/cleaned, it is dumped in the raw format from the google sheet. Oscar Baruffa gives a very good overview why this might be a good dataset for a data cleaning exercise and I urge you to check out his website here. The website also includes a link for the google form, it would be worthwhile to check out the form to better understand the cleaning process.
Most questions on the form are self explanatory, I add below questions from the form and their brief descriptions.
| Column | Description | Is Dropdown | Is Multi-Selection Allowed |
|---|---|---|---|
| Timestamp | Records the time of data entry | No | No |
| How old are you? | Age of the respondent | No | No |
| What industry do you work in? | Industry of employment | Yes | Yes |
| Job title | Title of the respondent's job | No | No |
| If your job title needs additional context, please clarify here: | Additional information about the job title | No | No |
| What is your annual salary? (You'll indicate the currency in a later question. If you are part-time or hourly, please enter an annualized equivalent -- what you would earn if you worked the job 40 hours a week, 52 weeks a year.) | Annual salary of the respondent | No | No |
| How much additional monetary compensation do you get, if any (for example, bonuses or overtime in an average year)? Please only include monetary compensation here, not the value of benefits. | Additional monetary compensation received by the respondent | No | No |
| Please indicate the currency | Currency of the respondent's salary | Yes | No |
| If "Other," please indicate the currency here: | Additional information on currency if "Other" is selected | No | No |
| If your income needs additional context, please provide it here: | Additional context related to respondent's income | No | No |
| What country do you work in? | Country of employment | Yes | Yes |
| If you're in the U.S., what state do you work in? | State of employment (for U.S. respondents) | Yes | Yes |
| What city do you work in? | City of employment | No | No |
| How many years of professional work experience do you have overall? | Total years of professional work experience | Yes | No |
| How many years of professional work experience do you have in your field? | Years of professional work experience in the respondent's field | Yes | No |
| What is your highest level of education completed? | Highest level of education attained by the respondent | Yes | No |
| What is your gender? | Gender of the respondent | Yes | No |
| What is your race? (Choose all that apply.) | Race or ethnic background of the respondent | Yes | Yes |
Form Design.
Although the form is well prepared and makes good use of form features with strict validations, there are few points we need to note when looking at the data.
- How old are is you is given as radio button, could have been asked either as a Year of Birth or just a number indicating age giving more granular data.
- The country, state and city could be better represented as a hierarchy reducing data errors, it is understandable to not include cities as it would greatly increase the metadata attached to the form. But it is always better to reduce data errors at source. Alternatively, city code could be taken as they are pretty standardised and can greatly reduce data errors when finding the full geographical heirarchy for a location, although it might not be desirable in all cases.
- Professional experience and experience in the field could be structured a a number instead of ranges.
The above points need not apply to all forms since all data collection is context dependent. There are multiple reasons people choose to use follow specific methods, for instance using a range instead of taking a number could be done to reduce cognitive load on the person filling the form. Asking date of birth instead of an age range can make lot of people drop out of filling the form when the formed is asked.
Cleanup Process
We will use Python for the cleanup process along with several libraries including pandas, pycountry, nltk among others.
Lets start with checking the data in the country column.
| What country do you work in? | If you're in the U.S., what state do you work in? | What city do you work in? | |
|---|---|---|---|
| count | 28033 | 23022 | 27951 |
| unique | 374 | 133 | 4817 |
| top | United States | California | Boston |
| freq | 8986 | 2610 | 772 |
The country count already looks suspicious as there are a total of 195 countries in the world and the US has only 50 states while our data contains 374 countries and 133 cities respectively.
Lets look at some discrepencies in the country column.
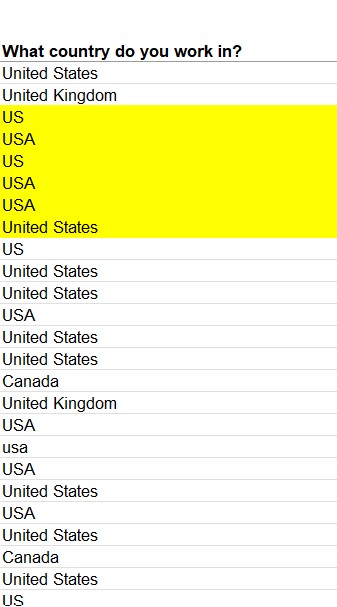
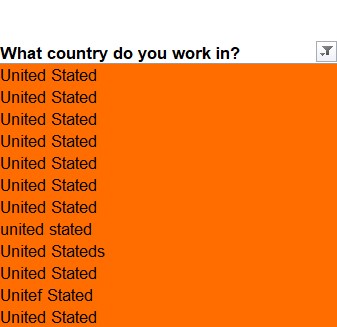

Issues identified in the country column:
- Different capitalisation: Eg usa vs USA
- Using Abbreviations Eg: US/USA/UK
- Using commonly used names for countries: Eg America instead of United States
- Spelling mistakes: Eg United States vs United Stated/denmark vs danmark
- Including a qualifier: Eg The Netherlands vs Netherlands
Here is our strategy to cleanup the country column.
| Step Name | Description |
|---|---|
| User-defined mappings | The method starts by defining a dictionary user_defined_dict which maps common variations or abbreviations of country names to their standard names. For example, 'us', 'usa', 'america', 'united states', etc., are mapped to 'United States'. This allows for quick lookups of frequently encountered country name variations. |
| Check user-defined mappings | The method checks if the provided country name c exists in the user-defined dictionary. If it does, the corresponding standard name is returned directly from the dictionary. |
| Direct lookup | If the country name is not found in the user-defined dictionary, the method attempts to perform a direct lookup using the pycountry library. If a direct match is found, the country name is returned. |
| Fuzzy search | If no direct match is found, the method attempts a fuzzy search using the pycountry library.If only one match is found, its name is returned. If multiple matches are found, 'Multiple Found'(which signifies an error code) is returned. |
| Fallback to Levenshtein distance | In case of an exception during the fuzzy search(if it cannot find anything for a country), the method falls back to a predefined list of country names and uses Levenshtein distance to find a close match with a distance of 1. If a match is found, it is returned. You can read more about Levenshtein distance here. |
| Handle errors | If an error occurs during the fuzzy search or if no suitable match is found using the fallback methods, 'Error Found' is returned. |
We also make use of a cache when running the above process since fuzzy search can be quite slow when running on even a small dataset of 20K records. Caching the result of the operation makes searching many folds efficient. The results are detailed below.
| What country do you work in? | country | |
|---|---|---|
| Count | 28033 | 28033 |
| Unique | 374 | 101 |
| Top | United States | United States |
| Freq | 8986 | 23053 |
We still have some countries left with ambiguous values after cleanup as shown below. A total of 114 are left, we can make sure to cleanup most of the remaining data as well but it would require us to maintain direct mappings of these values.

Next we will investigate salary column.
Again, we start by looking at descriptive statistics. The maximum number is too large for a realistic salary compared to the lower quartiles, what can be going on.
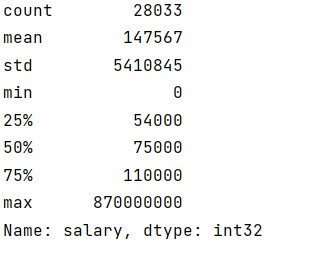
Looking at the dataset we quickly realise the data consists salaries from different nations in their local currencies which could lead to such discrepency.
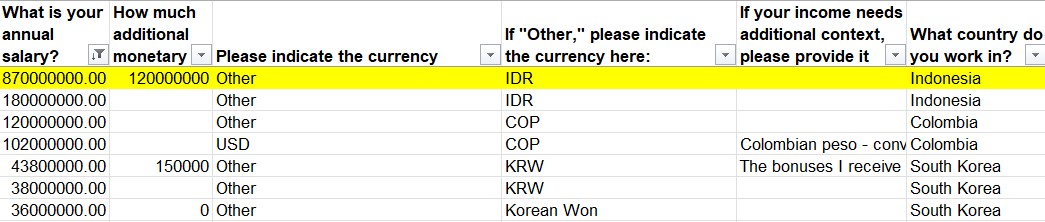
A quick conversion from the Indonesian Rupiah to UK Dollar shows that 870,000,000 IDR is equivalent to 54,888 US Dollar(as of the time of writing this blog) which does not seem implausible.
Next, we check the descriptive statistics for Salary for US citizens only using the country filter.
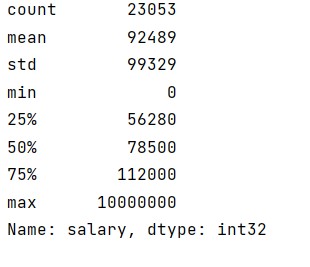
Although, $1million does not seem improbable, upon close inspection we find the record is most likely junk. Unfortunately, there is no easy way to find such records hence making data cleaning a repetitive and non-glamorous aspect of data analysis.
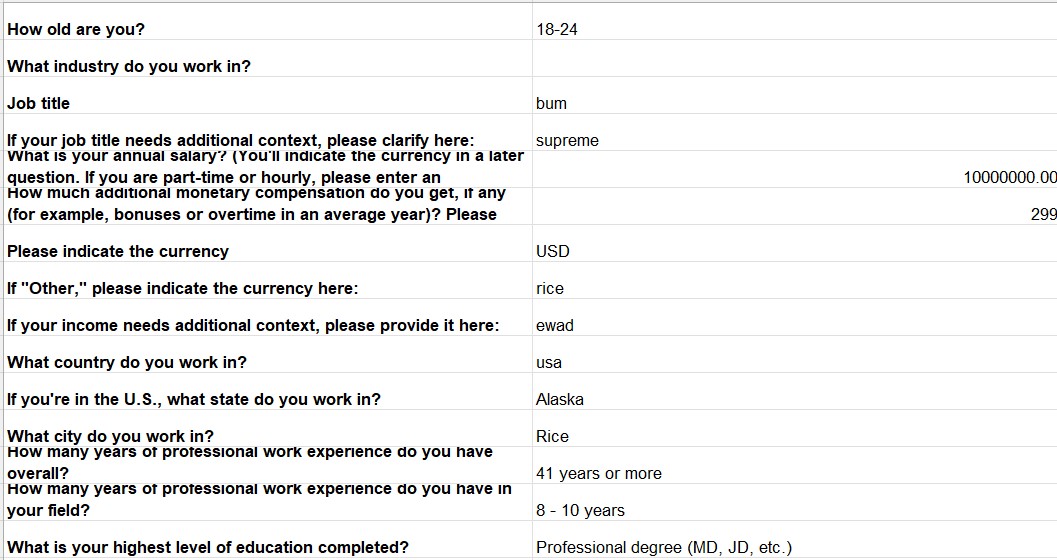
Removing the above record, we get the next highest salary in US of $5000044. To make further sense of the salary, we need to first standardise the currency we are dealing in. We have two columns for the same, one is a dropdown and other is a text values entered by the user in case currency is not listed.
We are going to continue our analysis into other variables into the next part and hope to uncover some new challenges and insights into the dataset.
Conclusion
Data cleaning is essential for ensuring accurate and reliable insights from datasets. In this blog, we navigated through the complexities of cleaning a real-world salary dataset, addressing challenges like inconsistent country names and outlier salaries. By employing manual mappings, fuzzy string matching, and error handling techniques, we successfully standardized and cleansed the data.
As we conclude, it's crucial to recognize data cleaning as an ongoing process. Continuous refinement and improvement are necessary to maintain data accuracy and readiness for analysis. Thank you for joining us on this journey, and we hope you found this exploration of data cleaning insightful.